MySQL Cluster读写分离验证-Amoeba环境搭建
对MySQL Cluster的学习还在继续,这次OneCoder是利用Amoeba搭建一个可读写分离、均衡负载的MySQL集群环境。
跟MySQL Cluster一样,安装的过程就是下载、解压、配置、启动。
Amoeba官方文档地址:http://docs.hexnova.com/amoeba/index.html
Amoeba项目地址:http://sourceforge.net/projects/amoeba/files/
解压后,在运行命令:
$>amoeba
验证的时候,就出现了第一个问题:
The stack size specified is too small, Specify at least 160k.
显然是JVM参数的问题。用vim编辑amoeba启动文件。修改其中的:
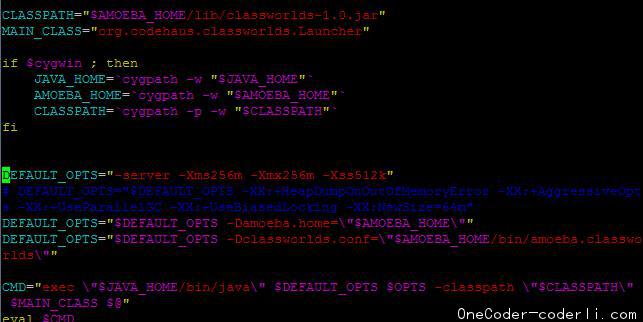
将图中选中行的DEFAULT_OPTS="-server ..."最后的 -Xss128k, 改为512k即可。验证通过。继续配置Amoeba。
以下内容摘自Amoeba官方文档:
Amoeba有哪些主要的配置文件?
想象Amoeba作为数据库代理层,它一定会和很多数据库保持通信,因此它必须知道由它代理的数据库如何连接,比如最基础的:主机IP、端口、Amoeba使用的用户名和密码等等。这些信息存储在$AMOEBA_HOME/conf/dbServers.xml中。
Amoeba为了完成数据切分提供了完善的切分规则配置,为了了解如何分片数据、如何将数据库返回的数据整合,它必须知道切分规则。与切分规则相关的信息存储在$AMOEBA_HOME/conf/rule.xml中。
当我们书写SQL来操作数据库的时候,常常会用到很多不同的数据库函数,比如:UNIX_TIMESTAMP()、SYSDATE()等等。这些函数如何被Amoeba解析呢?$AMOEBA_HOME/conf/functionMap.xml描述了函数名和函数处理的关系。
对$AMOEBA_HOME/conf/rule.xml进行配置时,会用到一些我们自己定义的函数,比如我们需要对用户ID求HASH值来切分数据,这些函数在$AMOEBA_HOME/conf/ruleFunctionMap.xml中定义。
Amoeba可以制定一些可访问以及拒绝访问的主机IP地址,这部分配置在$AMOEBA_HOME/conf/access_list.conf中
Amoeba允许用户配置输出日志级别以及方式,配置方法使用log4j的文件格式,文件是$AMOEBA_HOME/conf/log4j.xml。
修改dbServers.xml中的关于数据库链接的配置(一目了然)。
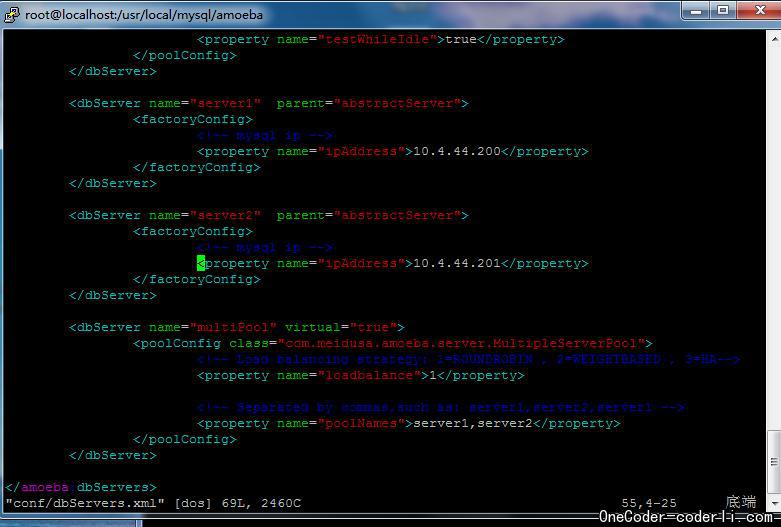
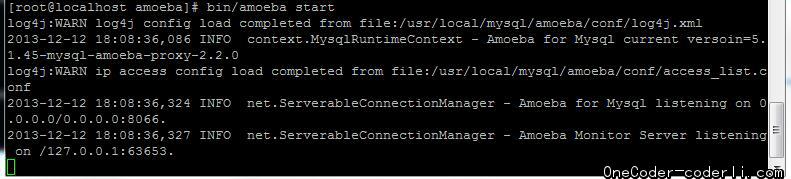
然后确认MySQL Cluster运行正常,再启动 Amoeba。
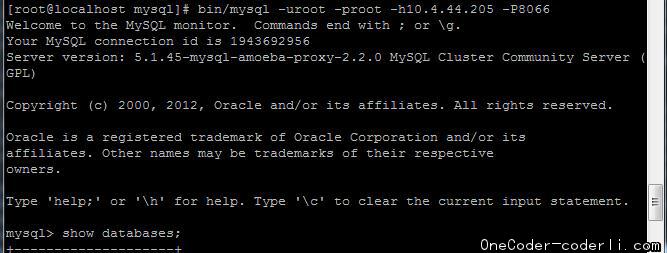
通过MySQL命令直接连接205进行测试。成功访问。
这里其实OneCoder遇到一个挺巧的问题,就是我环境中的server1暂时不好用,我仅仅配置了server2。可以启动,但是客户端连接就总报拒绝访问。几番检查,才在amoeba.xml中发现了一个默认节点的设置。还配置的server1,改成server2终于好用了。
 、
、
可以看到服务的version已经是mysql-amoeba-proxy了。并且通过show databases命令也可以正常列出数据库列表了。
所有代码已上传至Github:https://github.com/lihongzheshuai/yummy-code
GESP 学习专题站:GESP WIKI
"luogu-"系列题目可在洛谷题库进行在线评测。
"bcqm-"系列题目可在编程启蒙题库进行在线评测。
欢迎加入:Java、C++、Python技术交流QQ群(982860385),大佬免费带队,有问必答
欢迎加入:C++ GESP/CSP认证学习QQ频道,考试资源总结汇总
欢迎加入:C++ GESP/CSP学习交流QQ群(688906745),考试认证学员交流,互帮互助
